 본 블로그의 글은 (주)카디날정보기술이 저작권을 가지고 있으며, Create Common License의 Creative Commons Attribution-NonCommercial-NoDerivs 3.0 라이선스 아래에서 자유롭게 배포될 수 있습니다.
본 블로그의 글은 (주)카디날정보기술이 저작권을 가지고 있으며, Create Common License의 Creative Commons Attribution-NonCommercial-NoDerivs 3.0 라이선스 아래에서 자유롭게 배포될 수 있습니다.
본 블로그의 글은 (주)카디날정보기술이 저작권을 가지고 있으며, Create Common License의 Creative Commons Attribution-NonCommercial-NoDerivs 3.0 라이선스 아래에서 자유롭게 배포될 수 있습니다.
본 블로그의 글은 (주)카디날정보기술이 저작권을 가지고 있으며, Create Common License의 Creative Commons Attribution-NonCommercial-NoDerivs 3.0 라이선스 아래에서 자유롭게 배포될 수 있습니다.
The Data Structure of MongoDB (3)
7월 23rd, 2014
댓글이 없습니다.
글 : 이승용
이번에는 MongoDB 데이터 구조 연재 내용 중 세번째로 MongoDB의 인덱스 저장 구조에 대해 알아본다. MongoDB의 인덱스는 다른 NoSQL 보다 확장성과 유연성이 강력한 기능 중 하나이다. 하지만, 많은 장점에도 불구하고, 사용하면서 인덱스의 성능에 많은 의문점을 품은 개발자들도 많을 것이다. 이러한 의문점을 해결하는 방법은 MongoDB가 어떠한 형식으로 인덱스를 정의하고 구현하였는지 확인하는 것이 가장 좋은 해결책일 것이다. 이번 글에서는 조금이나 이러한 의문점을 해소시켜 줄 MongoDB 인덱스 구조에 대해서 알아본다.
MongoDB 인덱스 구조
모든 데이터베이스 시스템과 동일하게 MongoDB의 인덱스는 역시 B-TREE로 구현되어 있다. 일반적으로 우리는 자료구조 시간에 B-TREE의 구현에서 B-TREE 한 노드가 한 개의 데이터를 가지고 있는 방식으로 공부하였다. 하지만, B-TREE 한 노드에 한 개의 데이터를 저장하는 방식은 데이터를 저장하는 공간보다 B-TREE를 구성하는 링크가 데이터 보다 더 많은 저장공간을 차지하는 비정상적인 구조가 된다. 따라서, 실질적인 B-TREE를 이용한 데이터 관리는 MongoDB가 사용하는 방식처럼, B-TREE 노드에 한 개의 데이터가 아닌 복수개의 데이터를 저장하는 버켓BUCKET이라는 데이터 저장소를 사용한다.
![[그림 1] (a)한 개의 데이터를 가지는 B-TREE (b)복수개의 데이터를 가지는 버켓 구조의 B-TREE](http://mongodb.citsoft.net/wp-content/uploads/Post140723-01.png)
[그림 1] (a)한 개의 데이터를 가지는 B-TREE (b)복수개의 데이터를 가지는 버켓 구조의 B-TREE
[그림 1]에서 보는 것과 같이 (a)는 한 개의 데이터를 저장하고 있는 B-TREE를 보여주고 있고, (b)는 복수개의 데이터를 가지고 있는 B-TREE를 보여준다. 이 두 개의 B-TREE는 각기 장단점을 가지고 있다. (a)는 데이터의 삽입/삭제/검색 속도가 빠른 반면, 한 개의 데이터를 저장하기 위해 두 개의 링크 정보가 필요하다. 반면 (b)는 삭제에 따른 단편화 증상이 발생되고, 삽입되는 위치 설정과 검색이 (a)보다 느리다. 하지만, B-TREE를 구성하기 위한 링크 정보 저장공간이 (a)보다 작다는 장점을 가진다.
MongoDB에서 버켓이라는 메모리 블록을 사용하는 이유를 살펴보면, 대용량 데이터를 효율적으로 관리하기 위해 마치 해쉬hash 기법의 메모리 구성을 응용한 것과 같다. 근접한 키 값을 가지는 데이터를 한 버켓에 배치 함으로써 B-TREE를 구성하기 위해 들어가는 링크 주소 영역을 줄일 수 있고, 또한 검색을 위한 깊이deep를 줄일 수 있다는 장점이 있다. 하지만, 모든 데이터가 B-TREE로 구성된 것이 아니기 때문에, 버켓 안에 포함된 데이터를 검색하기 위한 순차 루프는 필요하게 된다.
![[그림 2] MongoDB의 B-TREE 구조](http://mongodb.citsoft.net/wp-content/uploads/Post140723-02.png)
[그림 2] MongoDB의 B-TREE 구조
[그림 2]는 MongoDB의 인덱스 버켓 구조를 보여준다. [그림 2]를 살펴보면 Version 0과 1이 존재하는 것을 볼 수 있다. Version 0과 1은 2010년 4월을 기준으로 이전 인덱스 구조를 Version 0로 표기하고, 이후 버전에는 Version 1 구조를 사용하고 있다. MongoDB에서 Version 0와 1 두 개의 구조를 공존하는 이유는 2010년 4월 이전에 사용되는 데이터 파일에 대한 호환성을 위해서이다.
Version 0와 1의 가장 큰 차이점은 Version 0에서 문제시 되던 인덱스의 메모리 크기와 관련 있다. Version 1은 Version 0의 B-TREE 노드의 헤더 영역과 인덱스의 데이터를 저장하기 위해 BSON 객체를 직접 쓰던 방식에서 헤더 영역의 불필요한 영역을 삭제하고, 인덱스 데이터를 BSON 객체가 아닌 데이터를 직접 저장하는 방법으로 메모리 효율성을 증가시켰다. 하지만, 버켓을 이용하는 기본 알고리즘은 변경되지 않았기 때문에, 메모리 효율성을 제외한 성능적인 이슈는 없다.
MongoDB에서 사용하고 있는 위치 정보(Parent Bucket, Next Bucket, Record Location, PrevBucket)인 DiskLoc 구조체는 총 8바이트의 구조를 가지고 있지만, 인덱스 Version 1의 위치 정보는 7바이트로 구성한 위치 정보 구조체를 사용한다. 8바이트 DiskLoc의 상위 4바이트인 볼륨 정보를 3바이트만 사용하는 것으로, Version 1의 볼륨의 최대 크기는 16진수로 0xFFFFFF까지만 가능하다. 만약 3바이트 영역을 벗어나는 경우는 인덱스의 크기를 벗어난다고 할 수 있다.[1]
[표 1] MongoDB인덱스 버켓의 헤더 구조
|
필드명 |
Version 0 크기 |
Version 1 크기 |
|
|
Parent Bucket |
8 |
7 |
B-TREE 노드의 부모 노드의 위치 정보 |
|
Next Bucket |
8 |
7 |
B-TREE 노드의 오른쪽 노드의 위치 정보 |
|
Size |
2 |
X |
버켓의 크기로 8192 값으로 고정되어 있음. Version 0에서만 사용되는 필드 |
|
Flags |
4 |
2 |
‘Packed’ 상태만 설정할 수 있으며, Packed 상태는 1의 값을 가진다. |
|
Empty Size |
4 |
2 |
버켓에서 사용하지 않는 공간의 크기 |
|
Top Size |
4 |
2 |
버켓에서 사용하고 있는 공간의 크기 |
|
Keys Number |
4 |
2 |
버켓에 저장된 키의 개수 |
[표 1]은 인덱스 버켓의 헤더 구조를 보여준다. Version 0에서는 예약 영역을 포함하여 총 40바이트의 헤더를 가지고 있고, Version 1에서는 22바이트의 크기를 가진다. 버켓의 크기는 Version 0에서는 8192바이트의 크기를 가지고 있고, Version 1에서는 8192바이트에서 16바이트를 제외한 8176바이트를 가진다.[2] 또한 Version 0는 최대 저장할 수 있는 키의 개수를 812개로 설정하고 있으며, Version 1은 1024개의 키 값을 가질 수 있도록 설정하고 있다. 최대 키 값의 개수는 한 버켓 안에 들어갈 수 있는 최대 키의 개수이다. Version 0과 Version 1의 버켓 크기가 16바이트 차이임에도 불구하고 최대 저장할 수 있는 키의 개수가 차이가 나는 이유는 BSON 객체를 직접 저장하는 방법과 데이터를 직접 저장하는 방법의 차이점에서 나타난다. 즉, BSON 객체로 키 값을 저장할 경우, BSON 객체가 포함하는 정보가 있기 때문에 BSON 객체의 헤더 정보로 인해 버켓 안에 많은 키를 저장하는 것은 힘들기 때문이다. 따라서, Version 1에서는 인덱스 정보의 효율성을 위해 BSON 객체보다 직접 데이터를 저장하는 방식을 채택하고 있다.
[표 1]의 flags 필드는 인덱스 버켓 안에 데이터 삭제로 인해 사용하지 않는 공간이 있을 경우, 이를 정리하는 옵션인 ‘Packed’를 설정할 수 있다. Packed 옵션이 설정되어 있다면, 인덱스 버켓에 사용하지 않는 공간이 있다는 것을 의미한다. 만약 버켓의 빈 공간을 재활용 할 수 있도록 재정렬하였다면 플래그의 Packed 옵션은 초기화 된다. 버켓을 이용한 B-TREE를 구현한 시스템의 단점으로 단편화 증상을 말하였다. 만약, 데이터의 삽입이 지워진 부분에 다시 삽입이 된다면(삭제된 키를 재 활용한다면) 단편화 증상이 없어질 수 있지만, 이러한 삭제 공간의 재활용은 쉽지 않다. 따라서, 일반 데이터베이스와 마찬가지로 MongoDB 역시 인덱스를 재정렬할 수 있는 기능을 가지고 있다.
[그림 2]의 Key Node는 고정된 크기의 배열과 같은 존재로 버켓 안에서 키 값이 저장된 위치와 도큐멘트의 위치, 그리고 B-TREE의 왼쪽 버켓의 위치를 저장하고 있다. [표 2]는 인덱스 버켓의 Key Node 구조를 설명한다.
[표 2] 인덱스 버켓의 Key Node 구조
|
필드명 |
Version 0 크기 |
Version 1 크기 |
|
|
Prev Bucket |
8 |
7 |
B-TREE 노드의 왼쪽 노드의 위치 정보 |
|
Record Location |
8 |
7 |
해당 키가 가리키는 도큐멘트의 위치 정보 |
|
Key Position |
2 |
2 |
버켓 안에 저장된 키 값의 위치 |
[그림 2]의 Key Object는 실질적인 키 값(데이터)을 저장하고 있는 것으로, 가변 길이의 데이터를 저장한다.[3] MongoDB는 가변길이 키 값을 저장하기 위해 고정 크기의 Key Node를 앞에 배치하고, 그 뒤에 키 값을 저장하는 Key Object를 배치하는 방법을 사용한다. 키 값은 Version 0에서는 BSON 객체 형식으로 저장하고 있지만, Version 1에서는 보다 많은 데이터를 버켓에 저장하기 위해 BSON 객체보다 실질적인 데이터만 저장하는 방식을 사용하고, 사용하고 이를 Element Data라고 정의하고 있다. 그렇다고, Version 1에서 Version 0이 사용하던 BSON 형식을 완전히 제거한 것은 아니다. 첫 번째 바이트를 IsBSON 타입으로 설정하여 0xFF의 값을 가지면 BSON 객체로 사용하고, 0xFF가 아니면 값 데이터를 직접 저장하는 방식으로 정의하고 있다.
Version 1이 사용하는 Element Data 형식은 첫 번째 바이트를 데이터 타입으로 설정한다. 데이터 타입은 [표 3]과 같다. 데이터 타입 바이트의 하위 4비트만을 사용하며, 데이터 형식 중 가변 데이터 형식은 cstring과 cbindata로 두 가지 유형을 정의하고 있다. [그림 3]은 Element Data의 구조를 보여준다.
[표 3] Version 1의 Key Object의 Element Data 타입
|
타입 |
값 |
길이[4] |
기타 |
|
cminkey |
1 |
1 |
|
|
Cnull |
2 |
1 |
|
|
cdouble |
4 |
9 |
|
|
cstring |
6 |
가변 |
타입 바이트 이후 1바이트가 문자열 길이를 저장한다. 따라서 문자열의 크기는 256바이트를 초과할 수 없다. |
|
cbindata |
7 |
가변 |
타입 바이트 이후 1바이트가 이진 데이터의 크기를 나타내는데 최대 크기가 32바이트를 초과하지 않는다. |
|
coid |
8 |
13 |
|
|
cfalse |
10 |
1 |
|
|
ctrue |
11 |
1 |
|
|
cdate |
12 |
9 |
|
|
cmaxkey |
14 |
1 |
![[그림 3] Element Data 구조](http://mongodb.citsoft.net/wp-content/uploads/Post140723-03.png)
[그림 3] Element Data 구조
Element Data의 cbindata 타입은 cstring 타입과는 달리 이진 데이터 크기가 아래와 같이 정의되어 있다. [그림 3]의 size 필드의 값에서 하위 4비트를 이진 데이터 유형으로 정의하고 상위 4비트를 크기로 정의하고 있다. 크기는 상수 값 BinDataCodeToLength 배열에 정의되어 최대 32바이트 값을 가진다.
const int BinDataCodeToLength[] =
{
0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 12, 14, 16, 20, 24, 32
};
int binDataCodeToLength(int codeByte)
{
return BinDataCodeToLength[codeByte >> 4];
}
하위 4비트의 이진 데이터 타입은 다음과 같이 정의되어 있다.
enum BinDataType {
BinDataGeneral = 0,
Function = 1,
ByteArrayDeprecated = 2,/* use BinGeneral instead */
bdtUUID = 3, /* deprecated */
newUUID = 4, /* language-independent UUID format across all drivers */
MD5Type = 5,
bdtCustom = 128
};
MongoDB의 인덱스는 다른 NoSQL과 달리 많은 인덱스를 설정할 수 있는 장점과 함께 복합 인덱스와 같은 유연한 특성을 가진다. 그리고, 빠른 데이터 검색을 제공하기 때문에, MongoDB의 인덱스는 많은 사람들에게 주목 받는 기능 중의 하나이다. 하지만, MongoDB의 인덱스를 사용하기 위해서는 충분한 이해가 필요하다. 앞에서 살펴본 봐와 같이 인덱스 버켓에 키 값(데이터)을 저장하기 때문에, 도큐멘트에 저장된 데이터와 중복 저장된다는 점과 함께, 빠른 인덱스 검색을 위한 입출력 기술이 별도로 구현된 것이 아니라, 운영체제가 제공하고 있는 Page Fault를 방식을 같이 사용하기 때문에, 메모리가 부족한 시스템에서는 오히려 검색 속도를 저하시키는 단점이 되기도 한다. 최악의 경우는 인덱스와 도큐멘트가 모두 메모리에 로드 되지 않았을 경우는, 한 개의 도큐멘트를 찾기 위해 두 번의 Page Fault가 발생할 수 있다. 즉, 적은 메모리를 사용할 경우는 인덱스를 설정하지 않는 것이 오히려 검색 시간을 줄일 수 있다.
MongoDB의 인덱스를 사용할 때는 다음의 사항을 고려하자.
- 인덱스를 메모리에 로그할 수 있을 정도의 충분한 메모리를 가지고 있는가?
- 인덱스를 설정한 데이터만으로 질의가 가능한가?
앞에서도 논하였지만, MongoDB의 인덱스는 키 데이터를 포함한 버켓 구조이다. 따라서, 해당 키 값만으로 질의를 수행한다면, 불필요한 도큐멘트의 로드가 필요없게 되므로, 검색과 결과가 동시에 수행되기 때문에 빠른 검색을 가능하다. 하지만, 반대로 인덱스 필드를 검색하여 도큐멘트의 다른 필드를 질의하는 경우라면 두 번의 메모리 액세스가 발생한다는 점에 주의하자.
[1] 총 7바이트는 2진수 256이므로 72,057,594,037,927,936 크기만큼 저장이 가능하다.
[2] Version 1에서 16바이트 모자라는 8KB인 이유는 버켓이 저장되어 있는 DiskLoc 위치를 같이 저장하는 여유 공간을 설정하기 위해서이다.
[3] 문자열을 인덱스로 선택하였다면 쉽게 이해될 것이다.
[4] 길이는 타입을 나타내는 1바이트를 포함한 크기이다. cdouble의 9바이트는 타입 1바이트와 double형 8바이트를 합한 크기를 말한다.
Categories: MongoDB
빅데이터 전용 서버, mdbSUITS 홈페이지 개설
3월 11th, 2014
댓글이 없습니다.
빅데이터 플랫폼을 위한 서버, mdbSUITS에 대해 보다 자세한 정보와 여러 자료들을 공유하기 위해
전용 사이트를 개설하였습니다. 주소는 다음과 같습니다.
여러분들의 다양한 의견과 관심 부탁 드립니다.
감사합니다.
Categories: 뉴스
The Data Structure of MongoDB (2)
1월 19th, 2014
댓글이 없습니다.
글 : 이승용
이번에는 MongoDB 데이터 구조(1)에 이어 두번째로 MongoDB가 데이터를 저장하는 기본 단위인 레코드record와 레코드들의 그룹핑인 익스텐트extent 구조에 대해 알아본다. MongoDB의 익스텐드는 자료 구조 관점에서 보면 연결되어 있는 레코드들의 헤더 역할을 수행하는 것 뿐만 아니라, 레코드 데이터를 로컬 스토리지에 저장하기 위한 파일로 처리한다.[1]
MongoDB 레코드 구조
MongoDB는 도규멘트document 로 구성된 데이터를 RDB의 열row과 같은 개념으로 처리한다. 하지만, MongoDB는 NoSQL의 특징인 RDB와는 달리 스키마schema 구조를 가지고 있지 않기 때문에 도규멘트에 저장되는 데이터 형식에 구애를 받지 않는다. 즉, RDB는 테이블에 속하는 모든 열이 같은 데이터 형식을 가지고 있어야 하지만, NoSQL은 열에 저장되는 데이터 형식이 상이하여도 문제가 발생되지 않는다.[2]
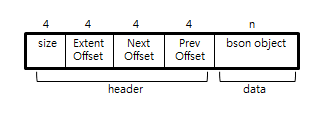
[그림 1] MongoDB의 레코드 구조
[표 1] MongoDB의 레코드 구조
|
필드명 |
내용 |
|
Size |
헤더를 포함하고 있는 레코드의 크기, BSON 객체의 크기는 Size 필드에서 헤더 크기인 16을 빼면 된다. |
|
Extent Offset |
해당 레코드가 속해 있는 익스텐션의 Offset 주소[3] |
|
Next Offset |
다음 레코드를 가리키는 Offset 주소 |
|
Prev Offset |
이전 레코드를 가리키는 Offset 주소 |
|
bson object |
도큐멘트를 구성하는 BSON 객체[4] |
[표 1]에서 레코드에서 저장되어 있는 모든 위치 정보(Extent Offset, Next Offset, Prev Offset)들이 4바이트 정수형 데이터로 저장한 이유는, 동일한 익스텐트 안에 저장되는 데이터이기 때문에 익스텐트 시작 주소의 상대 주소 값을 저장하여 중복된 데이터 영역을 없애 데이터 저장 크기를 줄일 수 있기 때문이다.
MongoDB 익스텐트 구조
MongoDB의 익스텐드는 레코드들의 그룹을 말한다. 익스텐드는 고유한 네임스페이스를 가지고 있기 때문에, 익스텐드에 포함된 레코드는 동일한 네임스페이스에 존재하는 데이터가 된다. 즉, 이전 글의 [그림 1]과 같이 MongoDB의 컬렉션은 한 개 이상의 익스텐드로 구성된다. MongoDB는 데이터베이스.컬렉션 형태의 데이터 표기법을 가지고 있다. 예를 들어, personal 데이터베이스의 user 라는 컬렉션이 존재한다고 가정하면, 데이터 삽입을 personal.user.insert( { personal_name : ‘이승용’ } ) 과 같이 사용한다. 이때 personal.user 의 형태가 네임스페이스를 의미한다. [그림 2]는 MongoDB의 익스텐드 구조를 보여준다.
[그림 2]와 구성된 MongoDB의 익스텐트는 한 개의 네임스페이스를 가지고 있기 때문에, 한 개의 컬렉션은 여러개의 익스텐트를 가질 수 있지만, 역은 성립하지 않는다.(한 개의 익스텐트에 두 개의 컬렉션이 저장되지 않는다.) [그림 2]의 위치 정보 – My Location, Next Extent, Prev Extent, First Record, Last Record – 들은 모두 8바이트 크기를 가지고 있다. 64비트 컴퓨터의 주소는 64비트 크기를 가지고 있기 때문에 8바이트 크기를 가진다. 그리고 size 필드가 4바이트로 규정되어 있다. MSBMost Significant Bit 를 제외하면 2GB의 크기 까지 익스텐트의 크기를 지정할 수 있다.
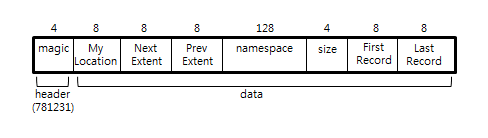
[그림 2] MongoDB의 익스텐트 구조
[표 2] MongoDB의 익스텐드 구조
|
필드명 |
내용 |
|
Magic |
4바이트 헤더이며, 정수 781231 값을 가진다. |
|
My Location |
해당 익스텐드가 저장된 위치 정보를 나타낸다. |
|
Next Extent |
다음 익스텐드를 가리키는 위치 정보 |
|
Prev Extent |
이전 익스텐드를 가리키는 위치 정보 |
|
Namespace |
해당 익스텐드의 네임 스페이스[6] |
|
Size |
해당 익스텐드의 크기 |
|
First Record |
해당 익스텐드에 포함된 첫번째 레코드 위치 정보 |
|
Last Record |
해당 익스텐드에 포함된 마지막 레코드 위치 정보 |
[1] MongoDB는 로컬 스토리지에 데이터베이스 명으로 확장자가 숫자로 증분하는 형태의 파일을 가진다. 예를 들어 test.1이라고 하면, test라는 데이터베이스의 첫번째 익스텐트를 의미한다.
[2] NoSQL의 기본 개념이 스키마 프리schema free 이기 때문에, RDB 사용하는 사용자가 가장 많이 혼동하는 부분이다. NoSQL을 RDB처럼 사용할 수 있지만, RDB처럼 데이터를 관리하지 않는다. 즉, 어떤 부분은 RDB보다 빠른 결과를 가져오지만, 어떤 부분은 RDB 보다 느린 경우가 발생한다.
[3] MongoDB는 모든 위치를 DiskLoc이라는 구조체를 사용하는데, volume 정보와 offset 정보 두 개를 가지는 구조체이다. 여기서 말하는 offset은 DiskLoc의 offset 주소와 동일하다.
[4] BSON 객체의 구조는 http://bsonspec.org/#/specification 참고.
[5] 필자는 혹시 MongoDB 개발자가 78년 12월 31일이라고 재미있는 상상을 해본다.
[6] MongoDB의 최대 네임스페이스 크기는 128바이트이다.
빅데이터를 위한 최고의 서버, “mdbSUITS”가 출시되었습니다.
1월 10th, 2014
댓글이 없습니다.
빅데이터 플랫폼을 위한 전용 서버, “mdbSUITS”가 출시되었습니다.
현재 오픈마켓에서 예약판매 이벤트를 진행하고 있습니다.
11번가, G마켓, 옥션에서 “mdbSUITS”를 검색해 보세요.
자세한 내용은 아래와 같습니다.

여러분의 많은 성원 부탁 드립니다.
감사합니다.
Categories: 뉴스
mongoDB Technical Conference, 성원해주신 덕에 잘 마쳤습니다!!
12월 11th, 2013
댓글이 없습니다.
2013년 12월 5일, 미세먼지가 가장 극점에 달하던 그날,
안좋은 일기를 무릎쓰고 참석해 주신 여러분께
진심으로 감사의 말을 전합니다.
기술적인 내용이 많은 컨퍼런스여서 지루해 하실까봐 걱정되었지만,
다행히도 좋은 평가들을 해주셨습니다.
앞으로도 좋은 내용으로 관련 세미나 등을 개최할 예정이오니,
많은 관심 부탁 드립니다.
다음은 컨퍼런스 진행 모습입니다.

[컨퍼런스 진행 전 모습]

[컨퍼런스 진행 모습]
아래는 컨퍼런스에서 발표한 자료 링크입니다.
Cardinal_MongoDB_Conference_Data
앞으로도 많은 관심과 성원 부탁 드립니다.
감사합니다.
Categories: 뉴스

The Data Structure of MongoDB (1)
10월 9th, 2013
댓글이 없습니다.
글 : 이승용
빅데이터가 소개되면서 NoSQL이 각광받게 되었으며, 그 중 MongoDB는 NoSQL에서 선두 자리를 차지하고 지속적으로 발전되고 있다.다. 오픈 소스인 MongoDB는 누구가 그 내부 구조를 살펴 볼 수 있음에도 불구하고 방대한 양 때문에 MongoDB에 대한 내부 구조에 대해 자세하게 논하지는 못하고 있다. 사실 끊임없이 업그레이드되는 프로젝트의 내부 구조를 매번 분석한다는 것도 매우 어렵다. 하지만, 필자는 이번 기회에 필자가 분석한 MongoDB의 내부 데이터 구조를 살펴봄으로써, NoSQL의 기술 트랜드가 어떠한 방식으로 발전되고 있는지 알아보고, 개선 방향에 대해서도 살펴보기로 한다. 이번에는 그 첫번째로 MongoDB에서 사용되는 데이터 구조의 용어를 기본 개념만 알아본다.
MongoDB의 데이터 구조는 크게 데이터를 저장하는 레코드record와 인덱스를 저장하는 버켓bucket으로 구성된다. MongoDB는 BSON 객체를 데이터 저장 단위로 사용하기 때문에, 저장하고 있는 모든 데이터를 BSON 객체의 이중연결리스트double linked list구조로 구성하고, BSON 객체를 저장하는 노드를 레코드로 정의한다. 반면 인덱스는 레코드에 저장된 데이터를 빠르게 찾기 위해 b-tree 형태로 저장된 노드 구조를 가지며, b-tree 노드를 버켓이라고 정의한다.
MongoDB는 대용량 데이터를 HDD에 쉽게 저장할 수 있는 단위로 레코드들을 그룹핑grouping하는데, 이를 익스텐드extent라고 한다. MongoDB의 익스텐드는 자료 구조 관점에서 보면 연결되어 있는 레코드들의 헤더 역할을 수행하는 것이지만, 이 익스텐드들을 이용하여 MongoDB는 HDD에 저장될 파일과 삭제된 레코드를 관리한다.
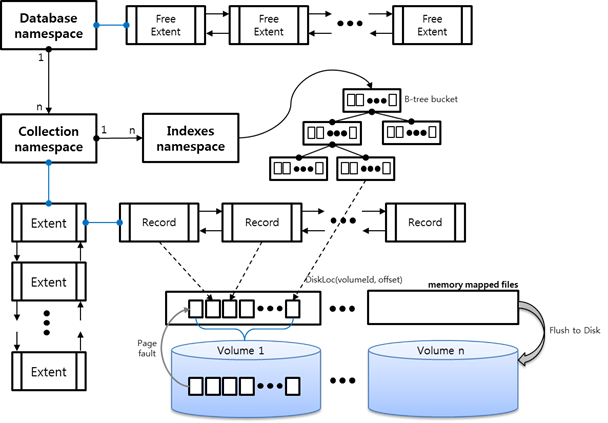
[그림 1] MongoDB 데이터 구조
[그림 1]은 앞에서 설명한 MongoDB의 데이터 구조가 유기적으로 수행되는 모습을 도식화한 것이다. 사용자가 하나의 데이터베이스를 만들었다면, MongoDB는 데이터베이스와 관련된 한 개의 네임스페이스namespace를 만든다.[1] 데이터베이스 네임스페이스는 RDB의 테이블과 동일한 MongoDB의 컬렉션collection 네임스페이스와 데이터베이스 별로 삭제된 레코드 리스트를 가지고 있는 프리 익스텐드Free Extent 리스트를 가진다. 컬렉션 네임스페이스는 사용자가 insert 질의를 통해 정의한 컬렉션 명으로 구성되며, 컬렉션 생성과 동시에 _id 필드의 기본 인덱스 네임스페이스를 가지게 된다. 만약 사용자가 _id 이외의 필드를 인덱스를 구성하였다면, 생성된 인덱스 필드에 하나의 인덱스 네임스페이스가 구성되고, 필드 값은 b-tree 형태로 인덱스를 구성한다.
MongoDB는 데이터를 저장하는 레코드나 인덱스를 저장하는 버켓이나 모두 데이터를 저장하는 공간이다. MongoDB의 데이터 저장소는 메모리 맵 파일Memory Mapped File을 사용한 가상 메모리를 사용한다. 가상 메모리는 시스템이 지원하는 운영체제 버전에 따라 가상 주소 공간을 할당 받게 되고 할당 받은 주소 공간을 마치 파일을 처리하는 방식으로 프로그램을 구성할 수 있다.[2]
[그림 1]과 같이 실질적인 데이터 저장 공간을 가지고 있는 레코드와 버켓은 그 크기에 맞는 가상 메모리의 주소를 가지고 있고, 사용자가 insert/update를 수행하였다면 MongoDB는 해당 레코드가 가리키는 가상 메모리 주소 공간에 데이터를 적재한다. 만약 사용자가 특정 위치의 데이터를 읽는다면, MongoDB는 해당 메모리 주소 공간에 할당된 데이터가 가상 메모리에 로딩되어 있는지 확인하고, 로딩되어 있지 않다면 파일에서 내용을 읽어 가상 메모리에 적재한다.[3]
또한 MongoDB는 백그라운드로 가상 메모리에 적재된 데이터를 HDD에 최대 2GB 단위로 파일을 구성한 볼륨volume으로 HDD에 데이터를 적재한다. 이를 플러쉬flush를 수행한다고 하며, 주기적으로 가상 메모리 공간에 로딩된 데이터를 HDD에 저장한다.[4]
[1] 사용자는 use 명령을 이용하여 데이터베이스를 선택한다.
[2] 32비트 OS에서는 가상 메모리의 한계로 2G만 선택할 수 있다. 여기서 2G는 Windows가 예약한 32비트 User Area 공간의 크기이다.
[3] MongoDB는 이러한 작업을 Page Fault Exception이 발생할 때 수행한다.
[4] 디폴트 주기 값은 60초로 설정되어 있다.
Open source ‘mongobird’
7월 17th, 2013
댓글이 없습니다.
(주)카디날정보기술
㈜카디날정보기술은 몽고버드(mongobird)라는 MongoDB를 위한 강력하고 유용한 모니터링 솔루션을 오픈 소스화 했다.
MongoDB는 비정형 데이터를 대량으로 저장할 수 있는 NoSQL 데이터베이스로 전 세계 데이터베이스 시장에서 10위 안에 들 정도로 급성장하였으며, NoSQL 부문에서는 줄곧 1위를 유지하고 있다. 더 많은 내용을 더 멀리 보여준다는 의미에서 이름 붙여진 몽고버드는 (초기 버전은 “Monad Management for MongoDB”라는 이름으로 출시된 바 있다) 보다 강력한 시각화 기술을 적용하고, 최신 버전의 MongoDB를 지원, 보다 많은 개발자들이 MongoDB를 이용한 개발 및 시스템 구성을 쉽게 할 수 있도록 도와준다.
또한, MongoDB의 각 지표 및 상황에 따른 매우 다양한 그래프들을 제공함으로써 운영자들이 쉽게 현재 상황을 파악할 수 있으며, 개발을 위한 상세 정보까지 표와 상세 그래프 등을 이용해 파악할 수 있게 해준다. 무엇보다 기존에는 MongoDB 도입 시 가장 큰 진입 장벽으로 여겨졌던 시스템의 효율적인 운영 및 관리를 해결해 준다는 점에서 큰 기대를 모으고 있다. 몽고버드는 대시보드를 이용한 전체 상황 파악, 모니터링을 통한 예/경보 기능, 각종 통계 그래프 기능을 제공하고, MongoDB의 새로운 버전에서 제공하는 기능들을 모두 수용하고 있으며 락 그래프 등을 별도의 메뉴로 제공한다.
몽고버드를 사용함으로써 시스템에서 발생하는 현상에 대한 확인 및 감시에 따라 시스템 재해를 예측(forecast)할 수 있고, 결과를 분석함으로써 향후 확장 시기 및 규모, 그 외 필요 사항들을 통찰(foresight)할 수 있으며 이에 따라 불필요한 자원 낭비를 방지할 수 있다. 몽고버드를 오픈소스화 함으로써 MongoDB를 이용한 각종 솔루션 및 관련 연구가 활발히 진행되어 MongoDB Eco 시스템에 큰 도움이 될 것으로 기대하고 있으며 나아가 몽고디비 솔루션 자체가 더욱 더 향상될 것으로 전망된다.
㈜카디날정보기술은 이외에도 MongoDB를 보다 쉽게 활용할 수 있도록 다양한 솔루션을 연구/개발 중에 있으며 MongoDB 플러그 인 개념의 솔루션인 MongoDB Extensions 시리즈를 곧 발표할 예정이다. 몽고버드는 제품 페이지(http://mongobird.citsoft.net/)에서 내용 및 데모 버전을 확인, 다운로드가가능 하며 오픈 소스 공유 사이트인 GitHub 사이트(https://github.com/citsoft/mongobird)에서도 다운로드 하여 사용할 수 있다.
Categories: 뉴스
Live monitoring tool ‘mongoowl’
6월 27th, 2013
댓글이 없습니다.
(주)카디날정보기술
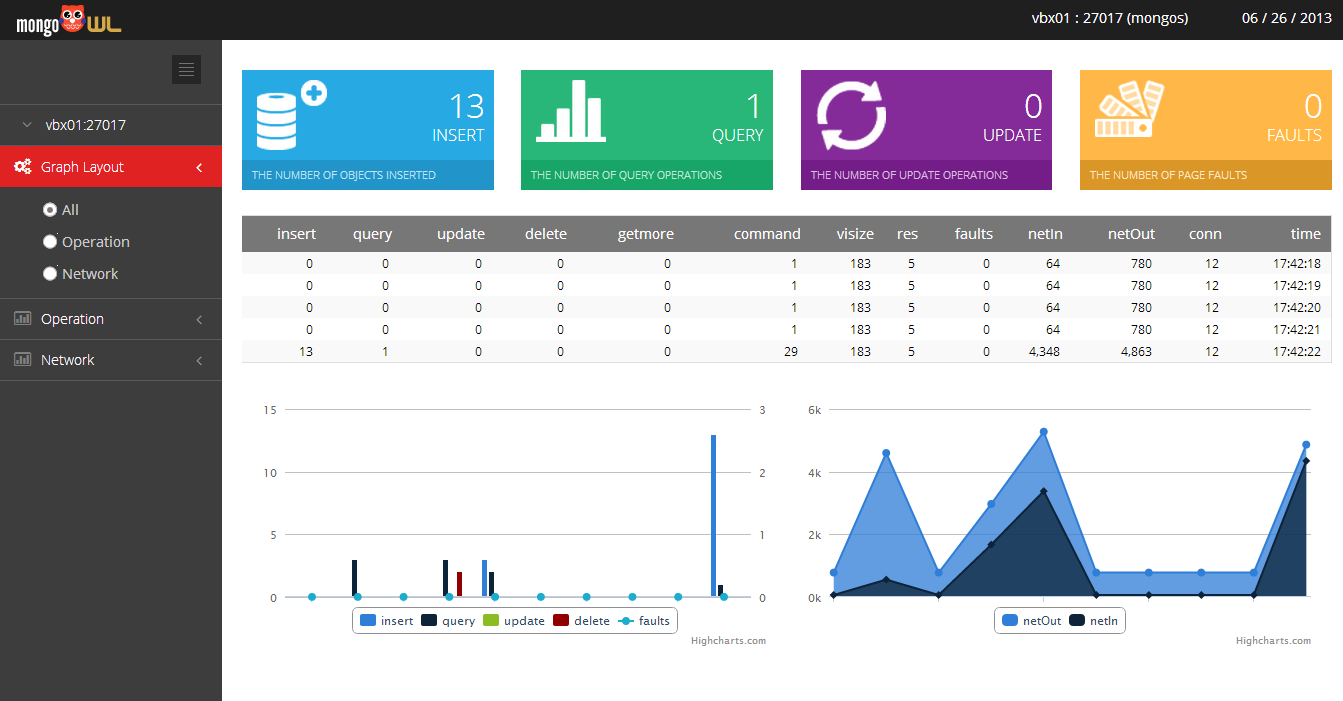
MongoDB 모니터링 툴인 mongostat의 웹 버전 mongoowl을 출시하였다. mongoowl은 1초 단위의 라이브 모니터링과 HTML5 기반의 동적 그래프 시각화를 지원하며, 모바일 디바이스를 통한 서비스가 가능한 any device를 지원한다. mongoowl은 2013년 7월 신소프트웨어 대상 추천작으로 전자신문에 아래와 같이 개제되었으며, 무료로 다운로드 받을 수 있다.
출처 : 전자신문 유선일 기자
카디날정보기술(대표 김지연)은 실시간 그래프 차트 기반의 모니터링 툴 `몽고아울(mongoowl)`을 출품했다.
분산 데이터베이스(DB) 몽고DB를 이용해 프로그램을 개발하면 실시간으로 변동사항을 파악해 개발·설계에 반영할 수 있다. 별도의 웹 컨테이너 없이 스탠드 얼론(stand alone) 형태로 구동된다. 실시간으로 주요 모니터링 요소를 대시보드에 그래프로 출력한다.
몽고아울은 대규모 분산환경 모니터링이 아닌 몽고DB 단일 데몬에 대한 실시간 모니터링용 제품이다. 적은 리소스로 구동 가능하고 직관적인 그래프로 구동 상황을 확인할 수 있다.
WAR 파일 실행만으로 간단히 설치할 수 있고, 설치 후 웹 브라우저에서 실행하는 간소한 절차를 통해 주요 모니터링 현황을 파악할 수 있다. 확인하려는 몽고DB 노드(node)의 IP와 포트 정보 및 사용자 권한 입력을 위한 인트로 페이지, 해당 노드의 모니터링 항목을 확인할 수 있는 대시보드 페이지로 구성된다.
대시보드 페이지에서는 인서트(INSERT), 쿼리(QUERY), 업데이트(UPDATE), 폴트(FAULT) 정보를 아이콘과 수치로 확인할 수 있다. 하단에 실시간 그래프를 출력해 직관적으로 현재 상태 정보를 파악할 수 있다.
[주요특징]
▶OS:JDK 호환 가능한 모든 OS
▶몽고DB용 실시간 그래프 차트 기반 모니터링 툴
▶(070)8255-6461
[김지연 대표 인터뷰]
“국내 개발자들이 몽고DB 적용을 주저하는 것은 우선 새로운 DB를 공부해야 한다는 부담감 때문입니다. 또 몽고DB는 콘솔 명령만 제공하기 때문에 지속적인 화면 모니터링을 통한 튜닝 포인트 확인이 어렵다는 문제도 있습니다.”
김지연 카디날정보기술 대표는 이 같은 문제를 해결하기 위해 종전 `몽고버드(mongobird)`라는 모니터링 전문 솔루션을 개발했고, 개발과정에서 얻은 핵심 기술과 가시화(Visualization) 기술을 접목해 이번에 몽고아울을 출시했다고 말했다.
김 대표는 “개발자들은 지속적으로 프로그램 개발 현황을 확인해 업무 효율을 극대화할 수 있다”며 “몽고DB의 특성을 직관적으로 파악할 수 있고 몽고DB 내부 구조도 보다 쉽게 파악 가능하다”고 말했다.
카디날정보기술은 개인 사용자나 연구 목적이면 무상으로 몽고아울을 제공하고 상업용으로 이용할 때는 별도의 라이선스 계약을 맺어 보급할 방침이다. 또 몽고DB 내부구조 연구 결과를 공유하기 위해 운영 중인 블로그 `몽고DB 인터널스(MongoDB Internals)`의 영문 서비스를 시작해 해외 시장 진출을 위한 기반을 다질 계획이다.
김 대표는 “이 같은 전략으로 우리의 높은 기술력을 인정받을 수 있을 것”이라며 “몽고DB 개발사인 텐젠(10gen)과 기술 파트너십도 맺을 예정”이라고 말했다. 이어 “수년 동안 몽고DB 연구개발(R&D)에서 전문적인 노하우를 쌓아 왔다”며 “일종의 `몽고DB 에코 시스템`이라고 할 수 있는 제품 라인업을 갖출 계획”이라고 덧붙였다.
MongoDB is an Open Source!
5월 9th, 2013
댓글이 없습니다.
글 : 이승용
MongoDB가 NoSQL의 강자로 자리잡기 시작하면서 장단점에 대한 기사를 종종 읽게 된다. 하지만, 세상만사 모든 일이 똑같지만 장점보다는 단점이 두각 되는 것은 어쩔 수 없는 이치인 것 같다. 2012년 초반에 PASTEBIN에 포스팅된 ‘Don’t use MongoDB’에도 MongoDB를 사용하면 안 되는 이유가 개제된 적이 있고, 거의 1년 만에 Bloter.net에서 다시 기사화된 것을 보면 MongoDB도 전세계적으로 유명한 데이터베이스가 되었구나 하는 생각이 든다.[1] 그리고, 1년 전에 논의된 내용이 아직도 유효한지는 모르겠지만,[2] 급변하는 IT 기술에 맞추어 볼 때, 필자는 오픈 소스 기술을 대하는 우리들의 자세가 문제가 있지 않나 생각해 본다.
대부분의 유명한 오픈 소스 기술들은 처음에 그들이 주장하는 기술이나 개념은 매우 놀라울 정도로 앞선 것들이다. 이러한 기술들이 개발자들에게 흥미를 유발시키고, 그리고 그 기술이 모든 것을 해결해 줄 수 있는 컴컴한 바닷가의 등불과 같이 안도의 길을 보게 한다. 기대가 크면 실망도 크기 마련이다. 해당 기술에 대한 정확한 분석이 있기 전까지 그들이 말하는 내용을 자기의 상황에 맞추어 모든 것이 해결된다고 판단해 버린 개발자는 신을 믿듯이 맹신하게 되고, 그 기대감이 자신의 기대치에 미치지 못한다고 판단하면, 홈쇼핑에서 물건을 잘 못산 것처럼 끔직한 비평가가 된다.
‘그들은 거짓말을 하고 있다.’ ‘그들이 다 된다고 했는데, 내가 원하는 기능이 아니다.’ 라는 식의 평가 없는 비평은 오픈 소스에 대한 바른 평가가 될 수 없다. 오픈 소스의 정신은 도전과 올바른 비평을 통해 발전의 방향을 공유하는 것이다. 만약 그들이 분석을 통한 비평으로 오픈 소스 기술을 올바르게 사용할 수 있는 방법을 연구하였다면, 전혀 새로운 기능들을 볼 수 있을 것이다. 오픈 소스는 상용화된 제품과는 달리 모든 기능들이 잘 정형화된 문서로 남지 않는다. 그렇다면, ‘어떻게 분석할 것인가?’ 바로 소스를 보는 것이다. 오픈된 소스를 통해 그들이 지원하지 않는 방법을 알아내고 이를 회피하는 방법 또는 보강하는 방법을 통해 새로운 기술을 습득하는 것이다.
그리고, 자신이 알아낸 기술을 인터넷을 통해 공유함으로써, 다음 버전에서 더 좋은 제품이 될 수 있도록 지원할 수 있어야 하며, 또는 그러한 기술을 통해 새로운 사업 아이템을 모색하는 것도 좋을 것이다. 그러면, 비평하는 개발자는 초기 맹신논자처럼 무조건 적인 맹신이 아니라, 분석 있는 날카로운 비평가가 될 수 있고, 자신의 실력이 올라가고 있음을 알 수 있을 것이다.
필자가 바라본 MongoDB는 다른 어떤 제품보다도 매혹적인 부분이 충분히 있으며, 또한 10gen이 왜 이렇게 만들었을까 하는 부분도 보인다.[3] MongoDB는 다른 솔루션과 마찬가지로 아무런 준비 없이 바로 대규모 시스템에 도입할 수 있는 제품은 아니다. 충분히 분석하고 연구함으로써 자신의 시스템에 맞게 구축할 수 있는 최상의 오픈 소스임에는 틀림없다.
[1] 2013년 5월 기준으로 MongoDB는 전세계 데이터베이스 시장에서 7위를 자리잡고 있다. 출처 : http://db-engines.com/en/ranking
[2] 해당 포스트가 개제될 때, 글을 쓴 사람이 사용한 MongoDB 버전은 1.8에서 2.0 버전으로 바뀌던 시점이다. 현재 MongoDB는 버전 2.4.3까지 업그레이드 되었으며, NoSQL은 1개월만 지나도 새로운 기술이 나오는 시점에 1년전 이야기를 하는 것은 바람직하지 않다고 본다.
[3] 이러한 장단점들은 필자가 본 사이트를 통해 다루어볼 것이다.
Translator
 | ") |  |  |  | |||||||||||||||||||||||||||||||||||||||||||