The Data Structure of MongoDB (2)
글 : 이승용
이번에는 MongoDB 데이터 구조(1)에 이어 두번째로 MongoDB가 데이터를 저장하는 기본 단위인 레코드record와 레코드들의 그룹핑인 익스텐트extent 구조에 대해 알아본다. MongoDB의 익스텐드는 자료 구조 관점에서 보면 연결되어 있는 레코드들의 헤더 역할을 수행하는 것 뿐만 아니라, 레코드 데이터를 로컬 스토리지에 저장하기 위한 파일로 처리한다.[1]
MongoDB 레코드 구조
MongoDB는 도규멘트document 로 구성된 데이터를 RDB의 열row과 같은 개념으로 처리한다. 하지만, MongoDB는 NoSQL의 특징인 RDB와는 달리 스키마schema 구조를 가지고 있지 않기 때문에 도규멘트에 저장되는 데이터 형식에 구애를 받지 않는다. 즉, RDB는 테이블에 속하는 모든 열이 같은 데이터 형식을 가지고 있어야 하지만, NoSQL은 열에 저장되는 데이터 형식이 상이하여도 문제가 발생되지 않는다.[2]
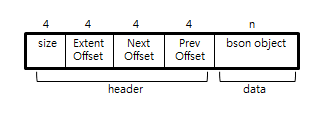
[그림 1] MongoDB의 레코드 구조
[표 1] MongoDB의 레코드 구조
|
필드명 |
내용 |
|
Size |
헤더를 포함하고 있는 레코드의 크기, BSON 객체의 크기는 Size 필드에서 헤더 크기인 16을 빼면 된다. |
|
Extent Offset |
해당 레코드가 속해 있는 익스텐션의 Offset 주소[3] |
|
Next Offset |
다음 레코드를 가리키는 Offset 주소 |
|
Prev Offset |
이전 레코드를 가리키는 Offset 주소 |
|
bson object |
도큐멘트를 구성하는 BSON 객체[4] |
[표 1]에서 레코드에서 저장되어 있는 모든 위치 정보(Extent Offset, Next Offset, Prev Offset)들이 4바이트 정수형 데이터로 저장한 이유는, 동일한 익스텐트 안에 저장되는 데이터이기 때문에 익스텐트 시작 주소의 상대 주소 값을 저장하여 중복된 데이터 영역을 없애 데이터 저장 크기를 줄일 수 있기 때문이다.
MongoDB 익스텐트 구조
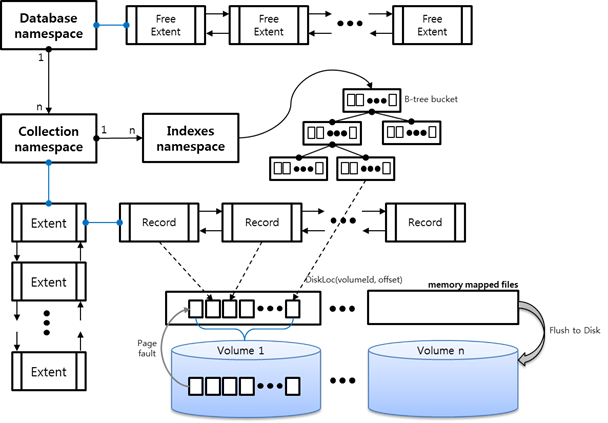
MongoDB의 익스텐드는 레코드들의 그룹을 말한다. 익스텐드는 고유한 네임스페이스를 가지고 있기 때문에, 익스텐드에 포함된 레코드는 동일한 네임스페이스에 존재하는 데이터가 된다. 즉, 이전 글의 [그림 1]과 같이 MongoDB의 컬렉션은 한 개 이상의 익스텐드로 구성된다. MongoDB는 데이터베이스.컬렉션 형태의 데이터 표기법을 가지고 있다. 예를 들어, personal 데이터베이스의 user 라는 컬렉션이 존재한다고 가정하면, 데이터 삽입을 personal.user.insert( { personal_name : ‘이승용’ } ) 과 같이 사용한다. 이때 personal.user 의 형태가 네임스페이스를 의미한다. [그림 2]는 MongoDB의 익스텐드 구조를 보여준다.
[그림 2]와 구성된 MongoDB의 익스텐트는 한 개의 네임스페이스를 가지고 있기 때문에, 한 개의 컬렉션은 여러개의 익스텐트를 가질 수 있지만, 역은 성립하지 않는다.(한 개의 익스텐트에 두 개의 컬렉션이 저장되지 않는다.) [그림 2]의 위치 정보 – My Location, Next Extent, Prev Extent, First Record, Last Record – 들은 모두 8바이트 크기를 가지고 있다. 64비트 컴퓨터의 주소는 64비트 크기를 가지고 있기 때문에 8바이트 크기를 가진다. 그리고 size 필드가 4바이트로 규정되어 있다. MSBMost Significant Bit 를 제외하면 2GB의 크기 까지 익스텐트의 크기를 지정할 수 있다.
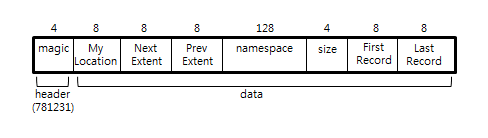
[그림 2] MongoDB의 익스텐트 구조
[표 2] MongoDB의 익스텐드 구조
|
필드명 |
내용 |
|
Magic |
4바이트 헤더이며, 정수 781231 값을 가진다. |
|
My Location |
해당 익스텐드가 저장된 위치 정보를 나타낸다. |
|
Next Extent |
다음 익스텐드를 가리키는 위치 정보 |
|
Prev Extent |
이전 익스텐드를 가리키는 위치 정보 |
|
Namespace |
해당 익스텐드의 네임 스페이스[6] |
|
Size |
해당 익스텐드의 크기 |
|
First Record |
해당 익스텐드에 포함된 첫번째 레코드 위치 정보 |
|
Last Record |
해당 익스텐드에 포함된 마지막 레코드 위치 정보 |



")


